j近期,一个话题引起热议:AI竞赛根本不能产生有用的模型,无法适用于现实世界;获胜的模型也不一定是最好的模型,冠军获胜只是因为他们运气好。那么,各种AI竞赛意义何在?作者的观点引发许多人反驳。
最近,一个新的大型CT脑扫描数据集被发布,其目的是训练模型以检测颅内出血。
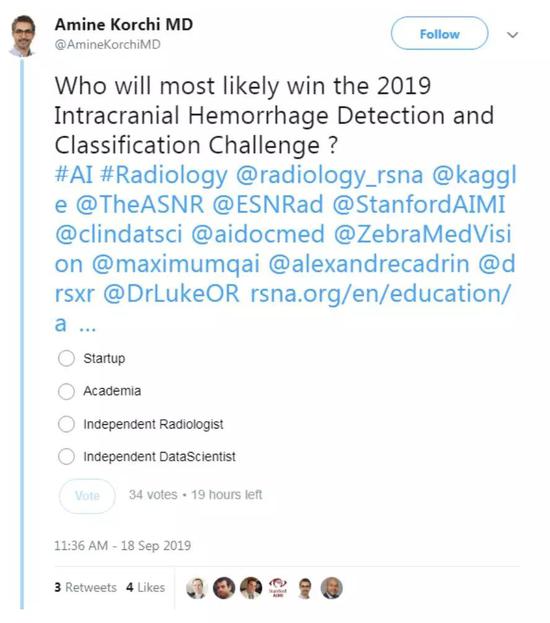
围绕该数据集,北美放射学会(RSNA)发布了一场Kaggle竞赛,有人在Twitter搞了个小投票:
引发讨论:
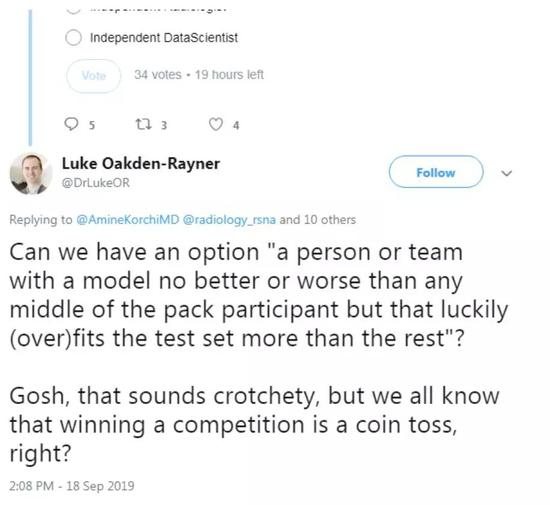
讨论继续,人们的想法从“但是既然有一个验证集,怎么会过拟合呢?”到“提出的解决方案永远不会被直接应用”(后者来自以前的竞赛获胜者)。
随着讨论的深入,我意识到,尽管我们“都知道”竞赛结果在临床意义上是有点可疑的,但我从未真正看到一个令人信服的解释,来解释为什么会这样。
这就是这篇文章的内容,希望能够解释为什么竞赛实际上并不是构建有用的AI系统。
让争论来得更猛烈些吧
那么,医疗AI领域的竞赛是怎样的呢?下面是一些选项:
让团队尝试解决一个临床问题
让团队探索如何解决问题,并尝试新的解决方案
让团队构建一个在竞赛测试集中表现最好的模型
浪费时间 |